Improving Exception Handling in NFI's Relay TMS
Why this matters: Shows ability to identify high-impact workflow problems, design targeted solutions, and achieve measurable operational improvements within an existing platform.
Team Composition
(5-6 members)Close partnership with field operations for real-world validation
TL;DR: Building a TMS Platform from the Ground Up
Scope:
Redesigned exception handling workflows within NFI's Relay Transportation Management System to reduce context switching, standardize resolution procedures, and improve operational response time for logistics teams.
Approach:
Conducted field research and event storming workshops to map real-time exception tracking, then designed a two-panel layout with a dedicated Exception Panel that keeps shipment context, exception details, and available actions within a single unified view.
What I did:
Led UX initiative to reimagine how exceptions were surfaced and resolved across operations teams. Created design patterns as reusable components within the Relay Design System and collaborated with engineering to optimize performance within LiveView constraints.
Impact:
Reduced exception resolution time by 28%, lowered user error rates by 37%, and achieved 80% component reuse across internal modules. Transformed exception handling from an error-prone, context-switching process into a reliable experience that operational teams trust.
Project Overview
The Challenge
In the legacy system, exception management felt disjointed and cognitively demanding. Dispatchers juggled multiple browser tabs, spreadsheets, and internal chat threads just to resolve a single issue. Information was fragmented across different screens, and the interface did little to indicate what needed attention first or what steps were available to resolve a problem.
- ⚠️Dispatchers frequently left the shipment view to find supporting data, losing context and requiring re-orientation
- ⚠️The same type of exception was handled differently depending on department, leading to inconsistent procedures
- ⚠️Key details like carrier updates, timestamps, and document links were buried under secondary tabs
- ⚠️Follow-ups and resolutions lived in email or Slack threads, not tracked within the TMS
- ⚠️No standardized visual indication of what needed attention first or what actions were available
Project Goals
The system needed to present context and action together—a single source of truth for exception handling. Our north star was to reduce cognitive load, standardize workflows, and improve operational response time.
- 🎯Reduce context switching by keeping exception data within the shipment view
- 🎯Guide user decisions by suggesting logical next actions directly in the interface
- 🎯Provide complete traceability with chronological history of changes and comments
- 🎯Standardize workflows by unifying exception types under one consistent UI pattern
- 🎯Scale efficiently while maintaining performance within Phoenix LiveView constraints
My Role & Responsibilities
UX Research & Design
- • Field research and contextual inquiry with dispatchers and operations teams
- • Event storming workshops to map exception workflows and pain points
- • User interviews across multiple departments to identify inconsistencies
- • Analysis of how exceptions were currently tracked and resolved
- • Wireframing, prototyping, and usability testing of the Exception Panel
- • Iterative feedback sessions with operations managers and stakeholders
Frontend Development
- • Designed and developed reusable Exception Card component variants
- • Implemented inline Timeline component for audit trail tracking
- • Created expandable Details Accordion for progressive disclosure
- • Built loading and error states for consistent user feedback
- • Optimized LiveView re-rendering to maintain performance with real-time updates
Cross-functional Collaboration
- • Worked daily with backend developers to align UI with exception data structures
- • Facilitated design reviews with operations teams to validate workflows
- • Provided designer-dev bridge to translate business requirements into technical constraints
- • Documented design patterns and component usage for cross-team adoption
- • Contributed to the Relay Design System with reusable exception handling patterns
Development Approach
This initiative focused on solving a specific pain point within the larger TMS platform: how to surface exceptions and guide their resolution without fragmentation. Our approach was to design a unified panel that brought together all the context and tools needed to resolve an exception without leaving the shipment view. I balanced creating a powerful, feature-rich solution with maintaining the simplicity and performance that LiveView promised.
Technology Stack
Frontend
- • Phoenix LiveView for reactive, real-time updates as exceptions changed
- • Tailwind CSS for consistent, scalable styling across exception components
- • Alpine.js for lightweight client-side interactions within the panel
Backend Integration
- • Real-time updates using Phoenix Channels to sync exceptions across teams
- • Elixir OTP for managing exception state and workflow transitions
- • Optimized queries to fetch exception history and related shipment data efficiently
- • PostgreSQL with strong schema design to track exception lifecycle and changes
Design Principles
- • Context Preservation: Never remove users from the shipment context. All exception data and actions live within the same view.
- • Progressive Disclosure: Surface only what users need, when they need it. Common fields visible, advanced details behind toggles.
- • Standardized Patterns: Use consistent component variants (Open, Resolved, Critical) across all exception types.
- • Real-Time Confidence: Live updates and timestamps give teams confidence that they're working with current data.
- • Traceability as Default: Every action recorded chronologically, creating an audit trail and helping teams learn from patterns.
Research & Discovery
Understanding Exception Workflows
Through field research and event storming workshops with operations teams, I mapped how users tracked and acted on exceptions in real-time. We brought together dispatchers, exception handlers, and operations managers to understand the full lifecycle of an exception—from when it was first detected to how it was resolved.
Context Loss as a Core Problem
Users frequently left the shipment view to find supporting data—carrier contact info, previous communications, document links—then had to mentally re-orient when returning to the exception. This context switching was the single biggest source of friction and contributed to both speed and error rates.
Inconsistent Procedures
The same type of exception (e.g., missing BOL, delivery delay) was handled differently depending on department. Some teams contacted carriers first, others updated documentation first. This inconsistency created confusion when teams collaborated and made training difficult for new hires.
Hidden Information
Key details were scattered—carrier updates buried in tabs, timestamps on different screens, document links in secondary menus. Users had to dig through multiple layers just to understand the full picture of why an exception occurred and what actions were available.
Discovery Methodology
Our research wasn't a one-time phase; it was embedded in our design process. Event storming sessions became a regular practice when starting new initiatives. We also gathered feedback directly during design reviews, where operations managers would point out missing use cases or workflows we hadn't considered. The act of visualizing exception flows often exposed edge cases that manual tracking had hidden.
Design Process
The design process for exception handling centered on understanding the full lifecycle of an exception and how to compress that experience into a single, focused view without losing information or flexibility.
Map Current State & Pain Points
We audited how exceptions were currently handled—which screens users visited, what information they needed at each step, and where they lost context or made errors. This revealed that exceptions required jumps between 3-5 different views.
Design Information Architecture
We organized exception data using progressive disclosure—pinning the shipment header at the top for context, showing common exception fields immediately, and hiding advanced details behind a "View More" toggle. This prevented cognitive overload while keeping power users satisfied.
Prototype Two-Panel Layout
We created low-fidelity prototypes showing the left panel retaining the shipment view, with a new Exception Panel on the right. This preserved shipment context while surfacing exception-specific actions. We tested this with real dispatchers to validate the approach.
Define Component Patterns
We documented reusable patterns: Exception Card Variants (Open, Resolved, Critical), Action Button States (Primary, Secondary, Confirmation), inline Timeline, and Expandable Accordion. These became foundational tokens for the Relay Design System.
Optimize for Performance
We worked closely with engineers to implement partial re-rendering in LiveView, ensuring that only the affected DOM nodes updated when exceptions changed. This maintained the snappy feel users expected while scaling to high-volume exception queues.
The Solution
We introduced a two-panel layout where the left side retained the consolidated shipment view, and the right housed a new Exception Panel. This panel dynamically surfaced exception details, recommended next steps, and allowed inline comments without leaving the main view. The result was a unified workspace where dispatchers could see everything they needed and act immediately.
A sticky header at the top of the Exception Panel preserved shipment context (ID, status, priority) as users scrolled through exception details. This ensured they never lost sight of which shipment they were working on and could quickly navigate back to the full shipment view.
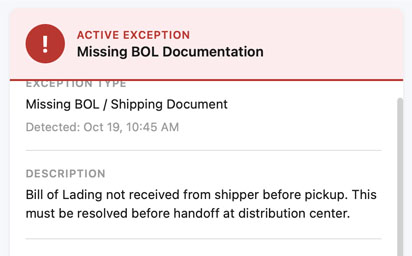
Exception details were organized by importance—common fields displayed immediately, advanced data accessible via "View More" toggle. This reduced cognitive load for routine exceptions while preserving power for complex edge cases.
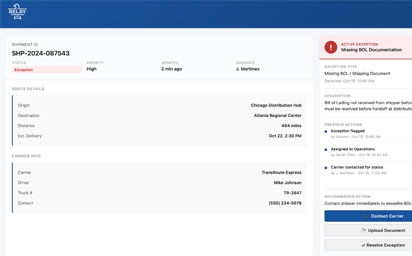
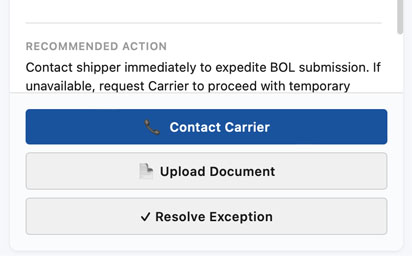
Suggested next steps appeared based on exception type and current state (e.g., "Contact Carrier," "Upload Document," "Resolve Exception"). Primary actions were highlighted prominently, with secondary options available below and confirmation states to prevent accidental actions.
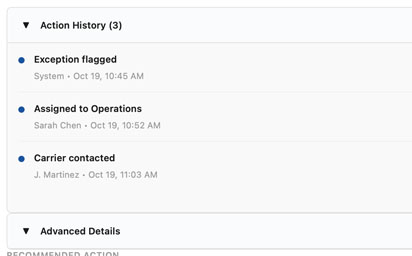
When other team members updated a shipment or exception, the panel updated instantly without requiring a manual refresh. Notification badges indicated incoming updates, and the timeline automatically reflected changes, giving teams confidence they were working with current data.
Workflow Consolidation
- ✓Moved from multi-tab exception handling to single-panel resolution
- ✓Embedded all exception data and available actions in one place
- ✓Reduced clicks from 7-9 per exception to 2-3 for common cases
Standardization & Consistency
- ✓Created consistent visual patterns for exception variants (Open, Resolved, Critical)
- ✓Standardized action sequences across departments
- ✓Documented procedures directly in the UI through progressive disclosure
Team Coordination
- ✓Enabled server-side visibility so all team members saw the same data in real-time
- ✓Integrated inline comments for context-rich communication
- ✓Created audit trail showing every action, change, and comment chronologically
Results & Impact
The new Exception Panel delivered measurable improvements across speed, accuracy, and team adoption. These results were based on internal operational data, user feedback, and cross-department adoption tracking.
Business Outcomes
User Feedback
"It feels like I'm finally working in one system, not five."
— Operations Manager, NFI Operations
"The timeline is a game-changer. I can see exactly what happened and who did what without digging through emails."
— Dispatch Supervisor, Fleet Operations
Long-Term Value
Based on the performance improvements and business impacts, the project achieved a positive return on investment. The long-term benefits include:
Scalability
Reusable component patterns enable rapid feature development without sacrificing consistency. New modules can adopt exception handling patterns immediately.
Operational Reliability
Standardized workflows and audit trails create a reliable, trustworthy experience that teams depend on for day-to-day operations.
Team Coordination
Real-time visibility and consistent procedures across departments transformed exception handling from an error-prone workaround into a core operational capability.
Reflections & Lessons Learned
Designing exception handling taught me that great enterprise design isn't about creating wow moments—it's about removing friction, standardizing behavior, and building trust through consistency. By anchoring workflows in context and scaling patterns through component thinking, we transformed an error-prone process into a reliable experience.
What Worked Well
✓Embedded Field Research
Spending time with real dispatchers showed us how exceptions actually flowed through the system, not just what management thought should happen. This grounded every design decision in reality.
✓Progressive Disclosure from Day One
We didn't try to cram everything into one view. Instead, we surfaced common cases simply and made advanced options available without clutter. This approach scaled from routine exceptions to complex edge cases.
✓Component System for Consistency
By documenting patterns and making them reusable, we ensured that future teams would build exception handling consistently, not reinvent it for every new module.
Challenges & Takeaways
⚠Performance vs. Complexity
LiveView required careful optimization to maintain speed as the Exception Panel became feature-rich. We implemented partial re-rendering to update only affected DOM nodes, teaching me the importance of designing with technical constraints in mind from the start.
⚠Change Management
Some users clung to legacy workflows despite the new system's advantages. Gradual rollout and targeted training sessions eased adoption, showing that even great UX needs organizational support.
⚠Documentation Debt
Early design decisions were tribal knowledge. We learned to capture the why behind patterns, not just the what, making it easier for future developers to extend patterns correctly.
Key Takeaways
This project highlighted several principles that I now apply to all of my UX work:
Context is Everything in Enterprise
Enterprise users work within complex operational constraints. Design that honors that context isn't just more usable—it's more likely to be adopted and improved upon by the team.
Standardization as Scaling Strategy
A good UI solves problems. A good design system prevents them. By thinking in reusable patterns early, we enabled the team to scale without losing consistency.
Invisible Design Earns Trust
Great design in operations doesn't draw attention to itself. It removes friction, guides behavior, and earns trust one interaction at a time. That's the goal in enterprise design.
Interested in working together?
I'm always open to discussing new projects, creative collaborations, or opportunities to be part of something meaningful. Feel free to reach out if you'd like to discuss how my skills and experience could benefit your team or project.